Menambah Worker Tidak Selalu Berarti Lebih Cepat: Eksperimen Message Queue dengan Redis Streams dan Go
Ketika membangun sistem notifikasi untuk backend e-wallet, pertanyaan pertama yang muncul biasanya sederhana: bagaimana caranya user dapat notifikasi setelah transfer berhasil? Tapi pertanyaan berikutnya lebih sulit: apa yang terjadi kalau proses pengiriman notifikasi gagal? Apakah bisa diretry? Kalau sudah retry berkali-kali tapi tetap gagal, ke mana message itu pergi?
Di eksperimen ini, saya mencoba membangun notification service menggunakan Go, Redis Streams, dan Docker — dengan tiga tujuan: memahami bagaimana message queue bekerja, memastikan tidak ada notifikasi yang hilang saat worker crash, dan mengukur apakah menambah worker benar-benar meningkatkan throughput.
Hasilnya mengejutkan.
Mengapa Notifikasi Tidak Boleh Diproses Inline
Cara paling sederhana mengirim notifikasi adalah langsung: setelah transaksi selesai, panggil fungsi kirim email, tunggu responnya, baru return ke user. Ini jalan, tapi ada masalah mendasar.
Kalau email server sedang lambat, user nunggu. Kalau email server down, transaksi gagal padahal uangnya sudah pindah. Kalau ada seribu user transfer bersamaan, seribu request semuanya nunggu giliran email selesai dikirim.
Solusinya adalah memisahkan dua hal yang sebenarnya independen: transaksi harus selesai secepat mungkin, notifikasi boleh diproses belakangan. Queue adalah jembatan di antara keduanya.
Desain: Producer, Stream, dan Consumer Group
Sistem ini terdiri dari tiga komponen. Producer mempublish event ke Redis Stream setiap kali ada transaksi. Stream menyimpan event tersebut secara berurutan dan persisten. Worker mengonsumsi event dari stream dan memproses notifikasinya.
Yang membuat Redis Streams menarik dibanding queue sederhana adalah consumer group — mekanisme yang memungkinkan beberapa worker berbagi beban dari satu stream, dengan jaminan setiap message hanya diproses oleh satu worker.
Retry dan Dead Letter: Ketika Gagal Bukan Akhir
Di kondisi nyata, pengiriman notifikasi bisa gagal. Email server bisa down, timeout bisa terjadi, koneksi bisa terputus. Tanpa mekanisme retry, message yang gagal diproses langsung hilang — user tidak pernah dapat notifikasi dan tidak ada yang tahu.
Solusinya adalah dua lapis perlindungan. Pertama, setiap message yang gagal diproses akan di-publish ulang ke stream utama dengan retry_count yang bertambah. Kedua, kalau sudah gagal tiga kali berturut-turut, message dipindah ke stream terpisah bernama notification:dead-letter — tempat parkir terakhir untuk message yang sudah menyerah, supaya bisa diinspeksi secara manual.
Ini yang terjadi di log saat simulasi email server down:
[RETRY 1/3] — user: user_123 | error: simulasi gagal: email server down
[RETRY 2/3] — user: user_123 | error: simulasi gagal: email server down
[DEAD LETTER] message dipindah setelah 3 retry — user: user_123Benchmark: Apakah Lebih Banyak Worker Berarti Lebih Cepat?
Setelah sistem berjalan, pertanyaan yang wajar muncul: kalau satu worker bisa proses X message per detik, apakah tiga worker bisa proses 3X?
Untuk mengukurnya, saya menjalankan tiga skenario dengan 1.000 message masing-masing.
Publish 1000 messages:

Worker 1:

Worker 2:

Worker 3:

Hasilnya berlawanan dengan ekspektasi. Semakin banyak worker, throughput justru turun.
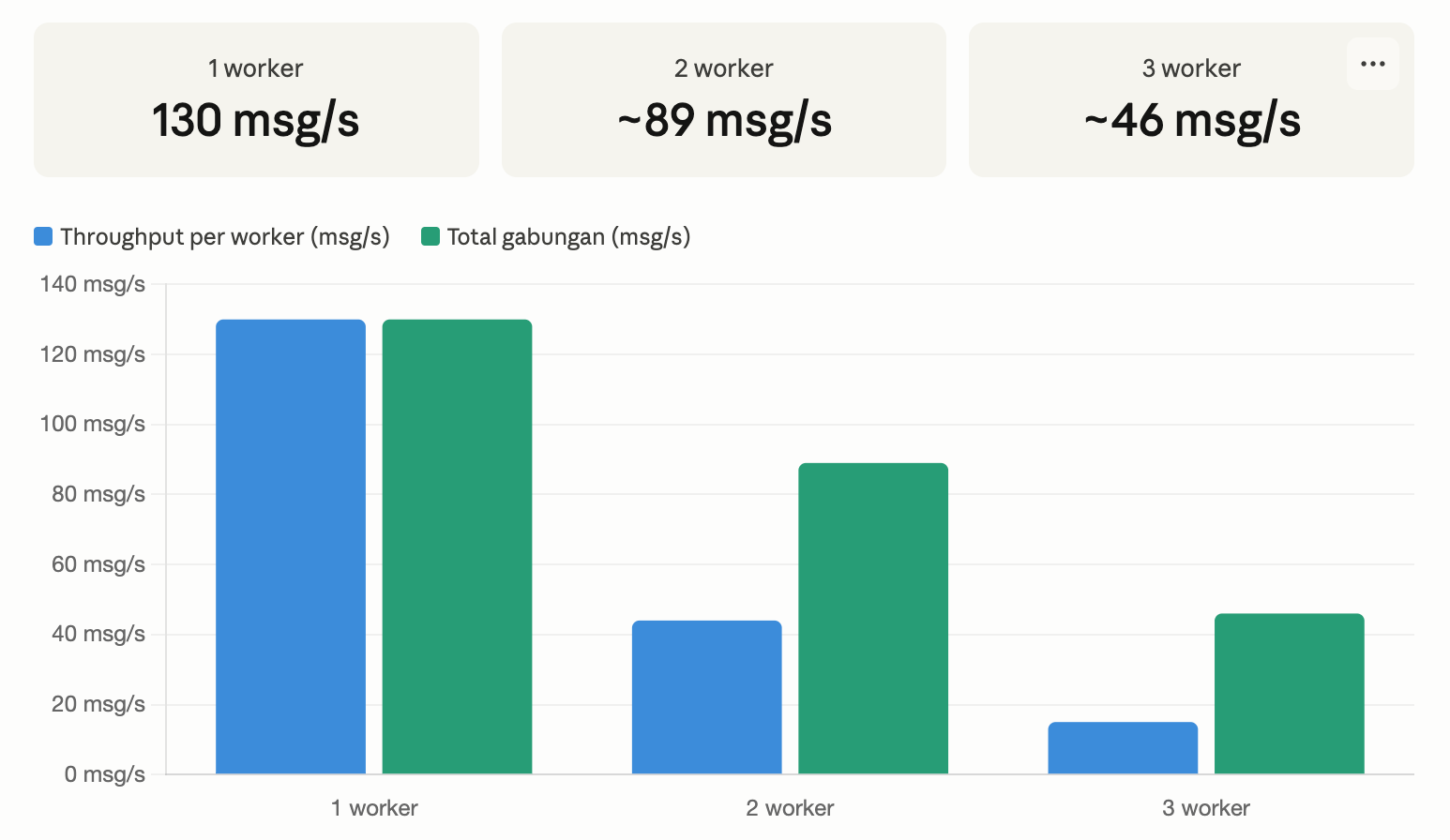
Jujur, saya awalnya bingung. Logikanya kan sederhana — kalau satu worker bisa proses 130 message per detik, dua worker harusnya bisa 260. Tapi hasilnya malah turun.
Saya sempat nanya ke AI, dan jawabannya masuk akal: semua worker jalan di laptop yang sama, berebut CPU, memory, dan koneksi Redis yang sama. Overhead koordinasi antar worker ternyata lebih mahal dari manfaat parallelism-nya di satu mesin.
Saya juga tanya salah satu mentor saya katanya di production yang sebenarnya, tiap worker jalan di server berbeda. Tidak ada rebutan resource. Di sana, menambah worker akan menghasilkan throughput yang proporsional. Pelajaran yang saya dapat: menambah instance bukan solusi ajaib kalau bottleneck-nya ada di shared resource.
Apa yang Dipelajari
Membangun notification service ini mengubah cara saya berpikir tentang sistem backend secara fundamental. Queue bukan sekadar "antrian" — ini adalah cara memisahkan pekerjaan yang harus cepat dari pekerjaan yang boleh lambat, sambil menjamin tidak ada pekerjaan yang hilang di tengah jalan.
Nah Dead letter juga bukan fitur tambahan, ini seharusnya wajib sehingga sistem tidak akan diam-diam membuang message yang gagal.
Dan benchmark yang hasilnya mengejutkan lebih berharga dari benchmark yang hasilnya sesuai prediksi, karena ia memaksa kita memahami mengapa.
Next Steps
Ada beberapa hal yang belum ada di eksperimen ini. Monitoring dead letter stream secara aktif, misalnya alert kalau ada message yang masuk ke sana. Dan yang paling menarik: mengulangi benchmark ini dengan worker di container terpisah untuk membuktikan hipotesis bahwa hasilnya akan berbeda.
Link project: github.com/abdulwahidkahar/notification-service